Recommendation Using Big Data
Traditionally, advertising is done through promotions such as billboards, newspapers and TV adverts. Although this remains an important kind of advertising, especially when aimed at people who don’t use the internet much, it can be costly and based on assumptions/generalisations about large groups of people.
However with Big Data it is possible to go deeper and market to individual users. Looking again at the MovieLens dataset from the post Evaluating Film User Behaviour with Hive it is possible to recommend movies to users based on their tastes using similar methods to those used by Amazon and Netflix.
Top Rated Movies
Looking again at the MovieLens dataset[1], and the “10M” dataset, a straightforward recommender can be built. Using the following Hive code, assuming the movies and ratings tables are defined as before, the top movies by average rating can be found:
CREATE TABLE f_m(movieID INT, avg_rating DOUBLE);
INSERT OVERWRITE TABLE f_m
SELECT MovieID,avg_rating
FROM
(
--get average and number of ratings for each movie
SELECT MovieID,avg(rating) AS avg_rating,count(rating) AS count_rating
FROM ratings
GROUP BY MovieID
) x
WHERE count_rating>=${hiveconf:sample_min}
ORDER BY avg_rating DESC
LIMIT ${hiveconf:topN};
--output movie titles by joining f_m and movies tables via movieID
INSERT OVERWRITE DIRECTORY '${hiveconf:OUTPUT}'
SELECT m.Title,f.avg_rating
FROM f_m f
JOIN movies m
ON f.MovieID=m.MovieID
ORDER BY f.avg_rating DESC;
The command line arguments -hiveconf topN=10 -hiveconf sample_min=20 set variables in Hive. topN is the number of movies in the final list and sample_min is the minimum number of ratings a movie has to have to consider its average rating. Single quotes e.g. ‘${hiveconf:OUTPUT}’ are used for string variables while the single quotes are left out for numerical variables.
This gives the following output:
Shawshank Redemption, The (1994) 4.457238321660348 Godfather, The (1972) 4.415085293227011 Usual Suspects, The (1995) 4.367142322253193 Schindler's List (1993) 4.363482949916592 Sunset Blvd. (a.k.a. Sunset Boulevard) (1950) 4.321966205837174 Casablanca (1942) 4.319740945070761 Rear Window (1954) 4.316543909348442 Double Indemnity (1944) 4.315439034540158 Seven Samurai (Shichinin no samurai) (1954) 4.314119283602851 Third Man, The (1949) 4.313629402756509
User Based Recommendation
There are some obvious problems with the above algorithm, mainly that users’ tastes are not looked at. Another is that many users will have seen most of the movies in the top 10, if not all of them.
By accounting for movies already seen by individual users, this script gives each user their own list of top rated movies:
--extract list of unique userIDs
CREATE TABLE users(UserID INT);
INSERT OVERWRITE TABLE users
SELECT DISTINCT UserID
FROM ratings;
--table listing top rated movies by average rating
--excluding movies that aren't rated by enough users
CREATE TABLE f_m(movieID INT, avg_rating DOUBLE);
INSERT OVERWRITE TABLE f_m
SELECT MovieID,avg_rating
FROM
(
--get average and number of ratings for each movie
SELECT MovieID,avg(rating) AS avg_rating,count(rating) AS count_rating
FROM ratings
GROUP BY MovieID
) x
WHERE count_rating>=${hiveconf:sample_min}
ORDER BY avg_rating DESC;
--list of top 5 movies not seen by each user
CREATE TABLE Unseen(UserID INT,MovieID INT);
INSERT OVERWRITE TABLE Unseen
SELECT UserID,MovieID
FROM
(
--get movie's ranking in UserID's list
SELECT UserID,MovieID,row_number() OVER (PARTITION BY UserID ORDER BY avg_rating DESC) AS rank
FROM
(
--generate table of movies in ufm not seen by user
SELECT ufm.*
FROM
(
--generate table of all possible user
--and movie combinations based on f_m
SELECT *
FROM users
CROSS JOIN f_m
) ufm
LEFT OUTER JOIN ratings r
ON ufm.movieID=r.movieID AND ufm.userID=r.userID
WHERE r.movieID IS NULL --exclude cases where user has seen movie
) x
) y
WHERE rank<=5;
--output movie titles by matching movieID with movie title
INSERT OVERWRITE DIRECTORY '${hiveconf:OUTPUT}'
SELECT U.UserID,m.Title
FROM Unseen U
JOIN movies m
ON U.MovieID=m.MovieID;
However the table f_m has 10,681 movies x 71,567 users ~ 764 million entries, which is unnecessarily large and inefficient. Eliminating as many poorly rated films as possible by adding the condition LIMIT ${hiveconf:sampleN} to the definition of f_m (after the line ORDER BY avg_rating DESC) controls the size of f_m and improves efficiency.
When generating a users’ list of top 5 unseen movies, if the value of sampleN is too low some users are recommended less than 5 movies. For this dataset a value of c.300 for sampleN is enough to sort this problem.
To fine-tune this further, genres and eras can be looked at. Defining the new table eras, where the table lists off all decades covered by the dataset, the following algorithm gives each user recommendations based on their favourite movie genres and decades:
--extract list of unique userIDs
CREATE TABLE users(UserID INT);
INSERT OVERWRITE TABLE users
SELECT DISTINCT UserID
FROM ratings;
--table listing of movies
--together with their average rating, genre and decade
--subject to a minimum ratings count
CREATE TABLE f_m(MovieID INT, Genre STRING, Decade INT, avg_rating DOUBLE);
INSERT OVERWRITE TABLE f_m
SELECT MovieID,genre,decade,avg_rating
FROM
(
--extract main movie features
--and get rating average and count
SELECT MovieID,genre,decade,avg(rating) AS avg_rating,count(rating) AS count_rating
FROM
(
--extract main movie features from table ratings
--using movies and genres tables
SELECT r.MovieID,g.genre,substr(m.Title,length(m.Title)-4,3) AS decade,r.rating
FROM Ratings r
JOIN movies m
ON r.MovieID=m.MovieID
CROSS JOIN genres g
WHERE instr(m.Genres,g.genre)>0
) x
GROUP BY MovieID,genre,decade
) y
WHERE count_rating>=${hiveconf:sample_min};
--table of each user's favourite combinations of genre and decade
CREATE TABLE Top5GE(UserID INT, Genre STRING, Decade INT);
INSERT OVERWRITE TABLE Top5GE
SELECT UserID,genre,decade
FROM
(
--rank user's preferences
--by number of movies in each genre and decade
SELECT UserID,genre,decade,row_number() OVER (PARTITION BY UserID ORDER BY cge DESC) AS rank
FROM
(
--count number of ratings
--by user and combination of genre and decade
SELECT UserID,genre,decade,count(rating) AS cge
FROM
(
--extract main movie features from table ratings
--using movies and genres tables
SELECT r.UserID,g.genre,substr(m.Title,length(m.Title)-4,3) AS decade,r.rating
FROM Ratings r
JOIN movies m
ON r.MovieID=m.MovieID
CROSS JOIN genres g
WHERE instr(m.Genres,g.genre)>0
) rmg
GROUP BY UserID,genre,decade
) x
) rank_rmg
WHERE rank<=5;
--table of top rated movies
--for each possible combination of genre and decade
CREATE TABLE GenreEraMovies(movieID INT, Genre String, decade INT, avg_rating DOUBLE);
INSERT OVERWRITE TABLE GenreEraMovies
SELECT movieID,genre,decade,avg_rating
FROM
(
--extract key movie features and match up to genres and decade
--rank movies in genre/decade combination by average rating
SELECT g.genre,e.decade,m.movieID,m.avg_rating,row_number() OVER (PARTITION by g.genre,e.decade order by m.avg_rating DESC) AS rank
FROM genres g
CROSS JOIN eras e
JOIN f_m m
ON m.genre=g.genre AND m.decade=e.decade
) x
WHERE rank<=${hiveconf:GEPool};
--recommend the best movie in each user's
--favourite combinations of genre and decade
CREATE TABLE Recom(UserID INT, MovieID INT);
INSERT OVERWRITE TABLE Recom
--most movies have multiple genres
--hence the DISTINCT keyword is used to remove duplicate recommendations
SELECT DISTINCT UserID,MovieID
FROM
(
--rank movies by average rating
--within each user's favourite combinations of genre and decade
--excluding movies already seen by user
SELECT tge.UserID,tge.MovieID,row_number() OVER (PARTITION BY tge.UserID,tge.genre,tge.decade ORDER BY tge.avg_rating DESC) AS rank
FROM
(
--table that matches top rated movies
--to each user's favourite combinations of genre and decade
SELECT t.*,ge.MovieID,ge.avg_rating
FROM GenreEraMovies ge
JOIN Top5GE t
ON ge.genre=t.genre AND ge.decade=t.decade
) tge
--remove movies already seen by user
LEFT OUTER JOIN ratings r
ON tge.UserID=r.UserID AND tge.MovieID=r.MovieID
WHERE r.UserID IS NULL
) x
WHERE rank=1;
--output movie titles by matching movieID with movie title
INSERT OVERWRITE DIRECTORY '${hiveconf:OUTPUT}'
SELECT R.UserID,m.Title
FROM Recom R
JOIN movies m
ON R.MovieID=m.MovieID;
Efficiency is controlled by the variable GEPool. After defining rank using the row_number() function, the condition WHERE rank<=${hiveconf:GEPool} limits the number of movies in this table. When GEPool is set to at least 50, users get at least 5 recommendations.
Collaborative Filtering
Collaborative filtering involves collecting information about user behaviour and making recommendations based on similarities between users.
Apache Mahout
Apache Mahout is a machine learning library in the Hadoop ecosystem that mainly includes algorithms for tasks such as recommendations, document clustering and document classification[2].
Mahout’s Item Based Recommender – Example
To illustrate the theory behind Mahout’s item based recommender, consider 4 users and 5 restaurants with the following user ratings:

Ratings are integer based from 0 to 10, with untried restaurants marked with an X. Now consider recommending a new restaurant to Sue.
Mahout computes the similarity matrix for the restaurants, S, where S_ij is the number of users that rate both restaurants i and j positively (i.e. a rating of at least 6), while S_ii is the number of users that rate restaurant i positively.

|
This is then multiplied by the vector of Sue’s ratings, R (where untried restaurants are given a 0):
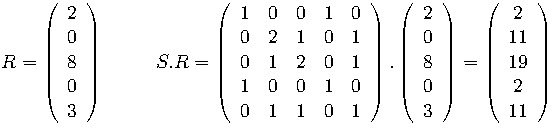
|
Ignoring restaurants Sue has already tried and normalising gives:

|
This predicts Sue will much prefer Restaurant 2 to Restaurant 4.
Mahout’s Item Based Recommender – Analysis
As with any mathematical model there is no “correct” way to make recommendations, however it is possible to see why this approach makes sense. Focusing on the relevant rows of S and R in the computation of S.R

|
this clearly recommends restaurants that are rated positively by users that also rate Sue’s favourite restaurants positively. Also the impact users’ ratings have on recommendation scores makes sense – a restaurant that is well rated by all users would get a high recommendation score, while a restaurant rated as 0 by all users gets a recommendation score of 0.
In practice S is a sparse matrix that is quite difficult to compute, as it involves a self join, however the latest editions of Mahout do not use MapReduce and are quite efficient.
Collaborative Filtering with MovieLens
An alternative to Mahout’s recommender is to compute the similarity matrix for movies in the MovieLens dataset. Then for any movie viewed by a user we can recommend films “often well rated with this movie”. The following Hive code does just that:
--get positively rated movies by UserID
CREATE TABLE sorted(userID INT,movieID INT);
INSERT OVERWRITE TABLE sorted
SELECT userID,movieID
FROM ratings
WHERE rating>=3.0; --condition for movie to be considered positively rated by user
--self-join positively rated movies
--identifying pairs of movies rated positively by the same user
INSERT OVERWRITE DIRECTORY '${hiveconf:OUTPUT}'
--recommend 5 movies for each movie
SELECT m1,m2
FROM
(
--rank movie pairs by the number of users that rate both positively
SELECT m1,m2,row_number() OVER (PARTITION BY m1 ORDER BY cnt DESC) AS rank
FROM
(
--identify pairs of movies positively rated by the same user
--and count how much this happens
SELECT s1.movieID AS m1,s2.movieID AS m2,COUNT(*) AS cnt
FROM sorted s1
JOIN sorted s2
ON s1.userID=s2.userID
WHERE s1.movieIDs2.movieID
GROUP BY s1.movieID,s2.movieID
) x
) y
WHERE rank<=5;
However this is quite inefficient, mainly because it uses a self join i.e. SELECT s1.movieID,s2.movieID,COUNT(*) AS count FROM sorted s1 JOIN sorted s2.
A better approach is to use the R function combn. For each user a list of movies they’ve rated positively is produced, from which all possible pairings of 2 movies is output. This can be done in Hive with a UDF defined in R, but using MapReduce is quicker with the following scripts:
#Mapper script to identify pairs of movies rated positively by the same user
#! /usr/bin/env Rscript
currentUserID <- ""
con <- file("stdin", open = "r")
while (length(line <- readLines(con, n = 1, warn = FALSE)) > 0)
{
split <- strsplit(line,"\t")[[1]]
if(currentUserID!=split[1])
{
if(currentUserID!="")
{
#remove last ":" from agg
agg <- substr(agg,0,nchar(agg)-1)
#parse individual movieIDs
movies <- as.integer(strsplit(agg,",")[[1]])
if(length(movies)>=2)
{
#output all possible pairings of movieIDs rated positively by same user
write.table(t(combn(movies,2)),
row.names = FALSE,col.names = FALSE,sep=",")
write.table(t(combn(rev(movies),2)),
row.names = FALSE,col.names = FALSE,sep=",")
}
}
currentUserID <- split[1]
agg <- ""
}
if(as.numeric(split[3])>=3.0) #condition to be considered rating as positive
agg <- sprintf("%s%s,",agg,split[2]) #aggregate up movieIDs, to be parsed
}
close(con)
if(currentUserID!="")
{
#remove last ":" from agg
agg <- substr(agg,0,nchar(agg)-1)
#parse individual movieIDs
movies <- as.integer(strsplit(agg,",")[[1]])
if(length(movies)>=2)
{
#output all possible pairings of movieIDs rated positively by same user
write.table(t(combn(movies,2)),
row.names = FALSE,col.names = FALSE,sep=",")
write.table(t(combn(rev(movies),2)),
row.names = FALSE,col.names = FALSE,sep=",")
}
}
#Reducer script - for each movie outputs the 5 movies
# it is most often paired with by the Mapper
#! /usr/bin/env Rscript
currentMovieID <- ""
current_pair <- ""
con <- file("stdin", open = "r")
while (length(line <- readLines(con, n = 1, warn = FALSE)) > 0)
{
if(line!="")
{
if(current_pair!=line)
{
if(current_pair!="")
{
#add movieID to the vector top5
#also add the amount of times it is paired with currentMovieID
#to the vector count5
top5 <- c(top5, strsplit(current_pair,",")[[1]][2])
count5 <- c(count5,count)
}
if(strsplit(line,",")[[1]][1]!=currentMovieID)
{
if(currentMovieID!="")
{
#sort count5, rearrange top5 based on this sort
#and keep the first 5 elements of these vectors
top5 <- top5[order(count5,decreasing=TRUE)][1:min(length(top5),5)]
count5 <- sort(count5,decreasing=TRUE)[1: min(length(top5),5)]
#output recommended MovieIDs
cat(sprintf("%s\t%s\t%d",currentMovieID,top5,count5),sep="\n")
}
top5 <- c()
count5 <- c()
currentMovieID <- strsplit(line,",")[[1]][1]
}
current_pair <- line
count <- 0
}
count <- count + 1
}
}
close(con)
if(current_pair!="")
{
#sort count5, rearrange top5 based on this sort
#and keep the first 5 elements of these vectors
top5 <- c(top5, strsplit(current_pair,",")[[1]][2])
count5 <- c(count5,count)
top5 <- top5[order(count5,decreasing=TRUE)][1:5]
count5 <- sort(count5,decreasing=TRUE)[1:5]
#output recommended MovieIDs
cat(sprintf("%s\t%s\t%d",currentMovieID,top5,count5),sep="\n")
}
This outputs pairs of MovieIDs, which can be converted into pairs of movie titles with a simple Hive script, using the table movies. Overall this algorithm’s efficiency is due to
combn being a vectorised function i.e. the speed of the calculation of combn(movies,2) is constant regardless of the size of the vector movies.
Looking at the results, one problem can be seen when looking at what gets recommended to users that have watched Toy Story:
Toy Story (1995) Dead Poets Society (1989) Toy Story (1995) Nightmare Before Christmas, The (1993) Toy Story (1995) Phenomenon (1996) Toy Story (1995) Raiders of the Lost Ark (Indiana Jones and the Raiders of the Lost Ark) (1981) Toy Story (1995) This Is Spinal Tap (1984)
Watching a children’s movie results in potentially inappropriate recommendations. A simplistic solution would be to have movies match by genre. However, given that most movies are under multiple genres, this doesn’t remove enough suspect matches to actually deal with the issue.
A better solution is to add rules to the code e.g. for each children’s movie only other children’s movies are recommended. Given that genre data and ratings data are in 2 different tables the best approach is, before running the MapReduce job, to start with the following Hive script to match up each rating with movie title and key genre:
INSERT OVERWRITE DIRECTORY '${hiveconf:OUTPUT}'
SELECT r.UserID,m.MovieID,if(instr(m.Genres,"Children")>0,"Children",
if(instr(m.Genres,"Documentary")>0,"Documentary","Standard"))
FROM ratings r
JOIN movies m
ON r.MovieID=m.MovieID
WHERE r.rating>=3.0
ORDER BY r.UserID;
Then some changes are also needed in the R scripts that make up the MapReduce Job. Firstly the line that aggregates movies, agg <- sprintf("%s%s,",agg,split[2]), must be changed as many movie titles will contain the character “,”, interfering with the use of the strsplit function to separate out movie titles. Instances of “,” are replaced with “:”, which isn’t in any movie title, while the line genres <- sprintf("%s%s:",agg,split[3]) is added to include a treatment of genres.
Secondly the variable filter is defined so only pairs of movies passing genre rules are matched i.e. for children’s movies only other children’s movies are recommended and for documentaries only other documentaries are recommended. The following code does that:
filter <- (genres[1,]==genres[2,] | genres[1,]=="Standard")
movies1 <- matrix(c(movies[,1][filter],movies[,2][filter]),ncol=2)
filter <- (genres[1,]==genres[2,] | genres[2,]=="Standard")
movies2 <- matrix(c(movies[,2][filter],movies[,1][filter]),ncol=2)
write.table(movies1,row.names = FALSE, col.names = FALSE,
sep=":", quote = FALSE)
write.table(movies2,row.names = FALSE, col.names = FALSE,
sep=":", quote = FALSE)
Already we see an improvement, with the following recommendations for Toy Story:
Toy Story (1995) Finding Nemo (2003) Toy Story (1995) Goonies, The (1985) Toy Story (1995) Harry Potter and the Prisoner of Azkaban (2004) Toy Story (1995) Nanny McPhee (2005) Toy Story (1995) Rescuers Down Under, The (1990)
Children’s movies from different eras, such as The Goonies, and that might not have necessarily been considered by users previously, are recommended under this system. However vintage movies, such as Vertigo, will not necessarily be paired with other vintage movies given the dataset’s bias towards modern movies:
Vertigo (1958) 12 Monkeys (Twelve Monkeys) (1995) Vertigo (1958) Being John Malkovich (1999) Vertigo (1958) Godfather, The (1972) Vertigo (1958) Indiana Jones and the Temple of Doom (1984) Vertigo (1958) Toy Story (1995)
Simply changing the filter variable to
filter <- ((substr(movies[,1],nchar(movies[,1])-4,nchar(movies[,1])-2)
==substr(movies[,2],nchar(movies[,2])-4,nchar(movies[,2])-2))
& (genres[1,]==genres[2,] | genres[1,]=="Standard"))
adds a match by decade. Now Vertigo gets the following recommendations:
Vertigo (1958) Diary of Anne Frank, The (1959) Vertigo (1958) Kiss Me Kate (1953) Vertigo (1958) People Will Talk (1951) Vertigo (1958) Show Boat (1951) Vertigo (1958) Suddenly, Last Summer (1959)
Conclusion
These are just a sample of many approaches that can be used to recommend. In practice, weighted combination of specific methods can be used, fined-tuned by the research of the post Evaluating Film User Behaviour with Hive . The more data, the better, so it should come as no surprise that companies reputed to have the most accurate recommenders are the likes of Amazon, Google, and Netflix.
Movie data such as country, language or director and user data such as sex or age is only a sample of what can be added for more accurate recommendations. Social networking data can also be used to recommend based on friends’ tastes and matching similar users.
The scale of this approach can be quite large and costly – while some pieces of code from the Netflix Prize were implemented by Netflix, the final winner wasn’t used as engineering costs outweighed accuracy benefits[3].
References
- ^ MovieLens Datasets
-
^ What is Apache
Mahout - ^ Netflix Recommendations: Beyond the 5 stars (Part 1) , April 6, 2012


Hi Murry thanks for your comment on my blog i’m beginner at hadoop i’m getting the following output when i enter ‘jps’ command the datanode and namenode is not visible why is it????
I am using a 64-bit Ubuntu OS
shashank@shashank-Inspiron-1564:~$ jps
4613 NodeManager
6307 Jps
4481 ResourceManager
3700 SecondaryNameNode
shashank@shashank-Inspiron-1564:~$
LikeLike
Shashank,
To be honest I have little experience playing around with the specific nodes themselves as I haven’t actually ever set up a multiple node cluster in Hadoop.
I’m not sure what you’re trying to do but Hadoop can be run on a single node and just requires being run from the command line. This tutorial got me started (http://www.michael-noll.com/tutorials/running-hadoop-on-ubuntu-linux-single-node-cluster/). Or I’ll use Amazon S3 for full-on Big Data, which takes care of all of that.
Otherwise addressing your problem directly try this – http://stackoverflow.com/questions/11889261/datanode-process-not-running-in-hadoop, unless you’ve already seen this.
Regards,
Liam
LikeLike
HI Liam. Hope you doing good.I am also a beginner in Hadoop doing my thesis on recommendation system if you don’t mind would your please share your email address with me.
LikeLike
Sorry for taking so long to get back to you, email me on email_liam_at@yahoo.ie. I’ll try help as much as I can, I’m very comfortable with Hadoop, although I’m not a professional in the area.
LikeLike
I am totaly a newb to hadoop so xcuse moi if it sounds silly… Been stuck for a while and none other than u cud help me to proceed.. As a part of my project i ve been surfing through papers related recommendation using hadoop/hive.. and i was glad to see your amazing work, was indeed a great help fr me to understand bettr.. well.. curtaining ma foreward let me put it straight..
i tried implementing this code and was getting an error.. could you please help me sort it out..
(portion of yr code that i was trying)
INSERT OVERWRITE TABLE mlonemb.Unseen
SELECT UserID,MovieID
FROM
(
SELECT UserID,MovieID,row_number() OVER (PARTITION BY UserID ORDER BY avg_rating DESC) AS rank
FROM
(
SELECT ufm.*
FROM
(
SELECT *
FROM mlonemb.dusers
CROSS JOIN mlonemb.f_m
)ufm
LEFT OUTER JOIN mlonemb.ratings r
ON ufm.movieID=r.movieID AND ufm.userID=r.userID
WHERE r.movieID IS NULL
) x
) y
WHERE rank<=5;
the error o/p:
FAILED: ParseException line 5:40 missing FROM at ‘(‘ near ‘(‘ in subquery source
line 5:41 cannot recognize input near ‘PARTITION’ ‘BY’ ‘UserID’ in subquery source
please help me brother..
LikeLike
Rimnesh,
I’ll take a look at this today and try get back to you ASAP. Luckily you caught me on a day off.
Regards,
Liam
LikeLike